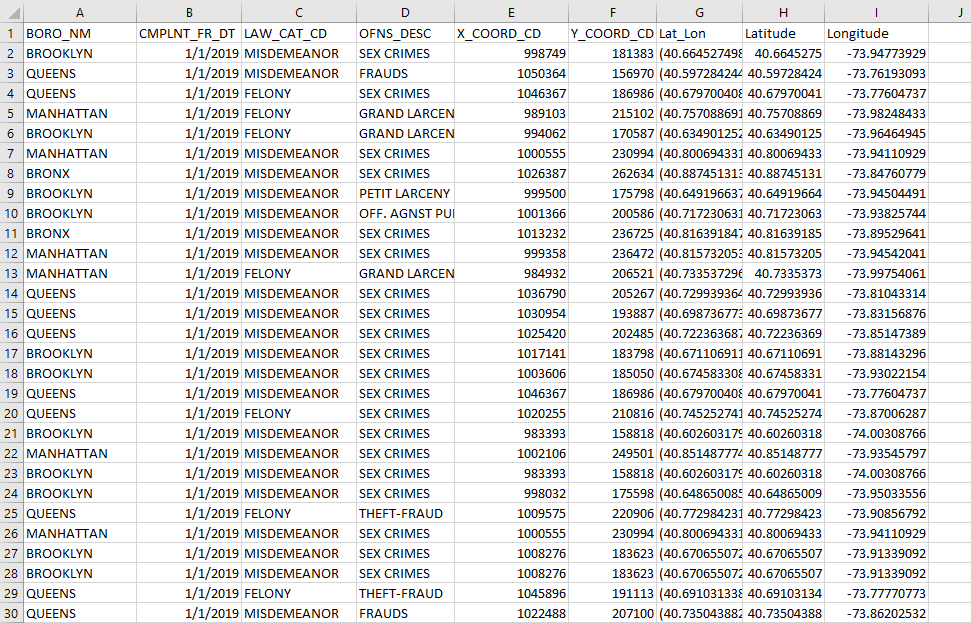
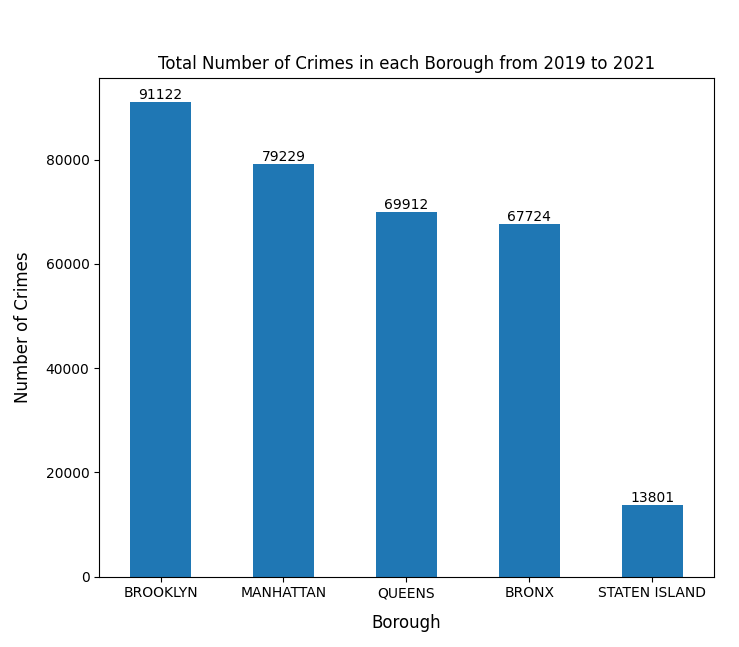
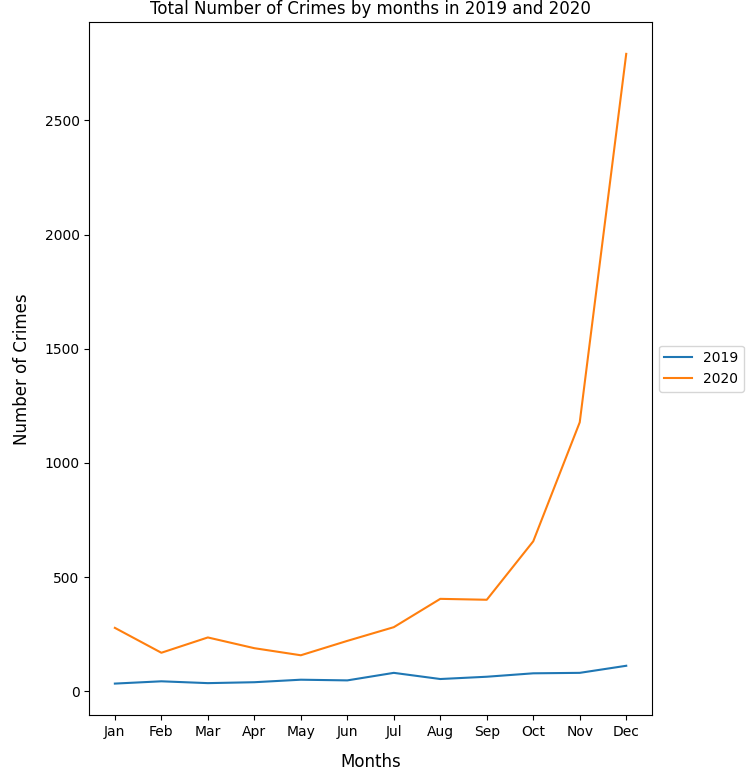
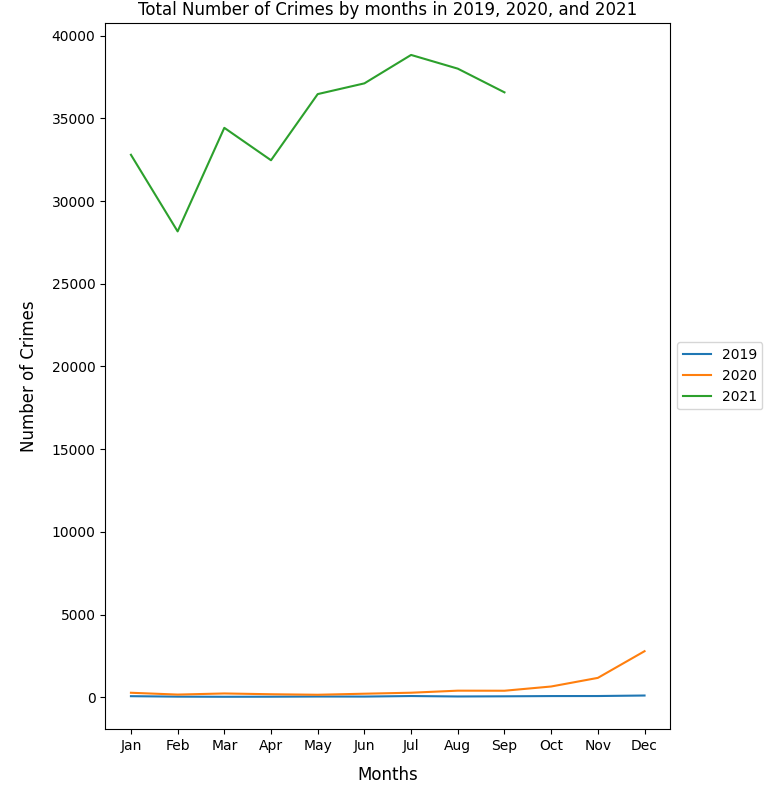
Using PandaSQL to get the desired columns and save it as a .csv file
import pandas as pd
import pandasql as psql
df = pd.read_csv('NYPD_Complaint_Data_Current_Year_To_Date_.csv')
# Using pandasql to pick out the desire columns
newDF = psql.sqldf("""
SELECT BORO_NM, CMPLNT_FR_DT, LAW_CAT_CD, OFNS_DESC, X_COORD_CD, Y_COORD_CD, Lat_Lon
FROM df
ORDER BY CMPLNT_FR_DT ASC
""")
newDF.to_csv("Specific_Cols.csv", index = False)